AI: Making an ML Model
Supervised / Unsupervised Learning
- Unsupervised learning uses unlabelled data
- For instance, an ML system is given a series of normal chest radiographs and learns how best to compress and uncompress them.
- This is known as an autoencoder.
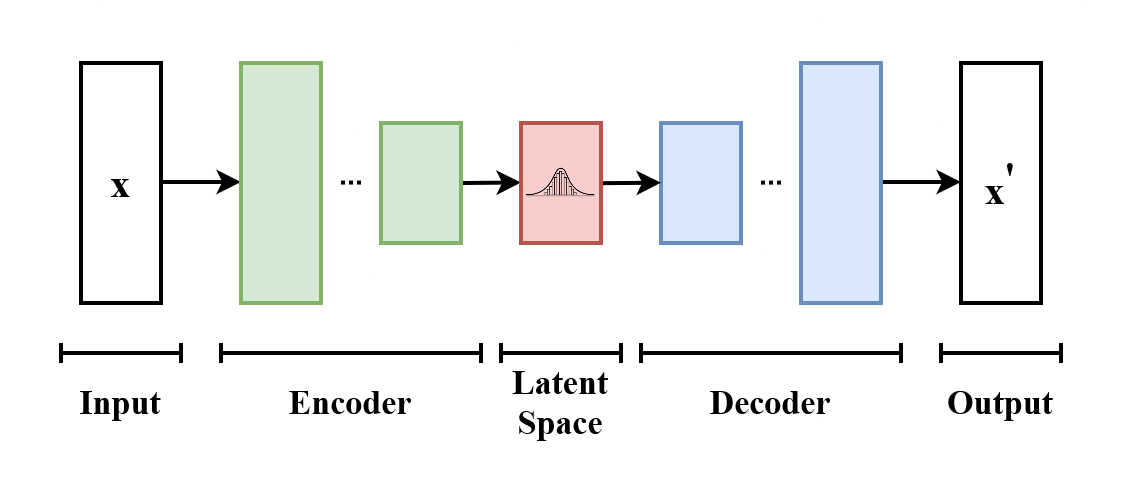
Variational Autoencoder - By EugenioTL - Own work, CC BY-SA 4.0, link here
Appreciate

Right??
Machine Learning Process
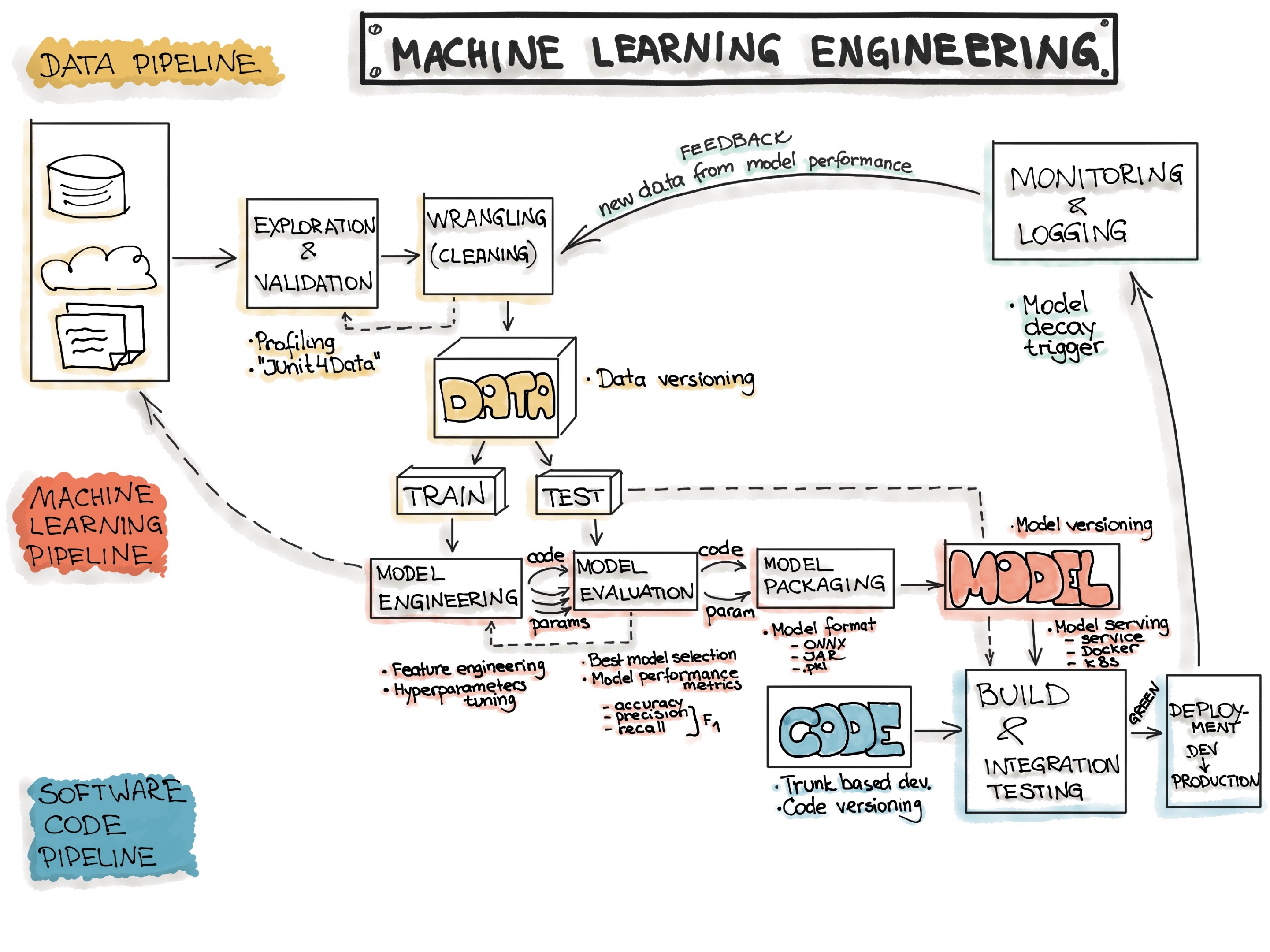
Bias in clinical applications
- Bias can come from many places during creation of a clinical dataset.
- Missing data for certain groups
- Lack of robust data collection protocols for researchers
- Biased sampling
- This can lead to algorithms that underperform for certain groups.
Source: [1] (see sources slide.)
Case Study 1 - Dermatology
- Convolutional neural networks can be trained to classify skin lesions.
- Dataset contains 5-10% images of lesions on black skin.
- Diagnostic accuracy halves when trialled with images of black skin.
Source: [1] (see sources slide.)
Case Study 2 - Heart Disease Predictors
- Predictive models for heart disease are often trained on datasets that have more data from male patients.
- How might this affect the clinical application of the tool?
Source: [1] (see sources slide.)
Example of data augmentation
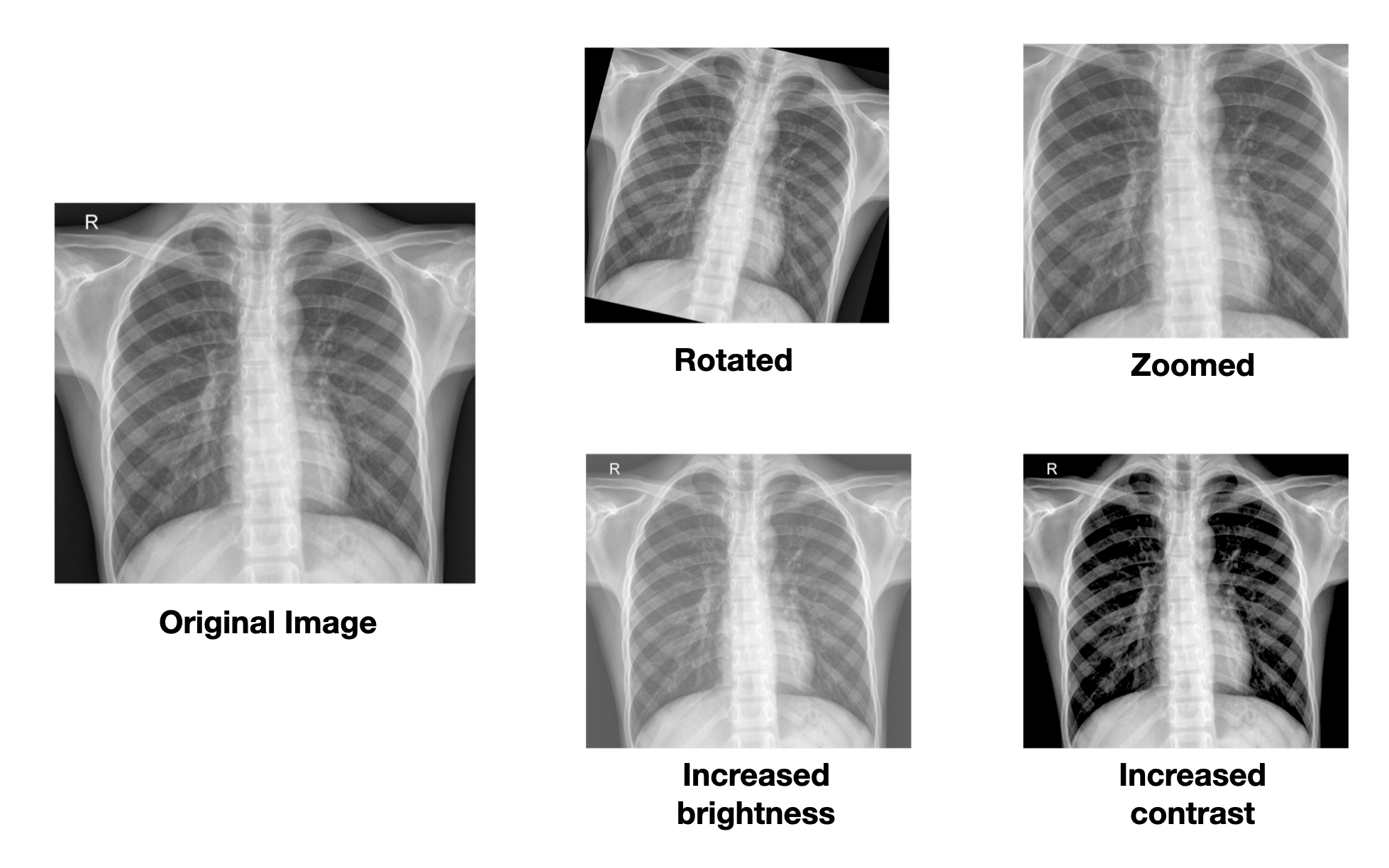
Examples of different data augementation techniques. Source: [2]
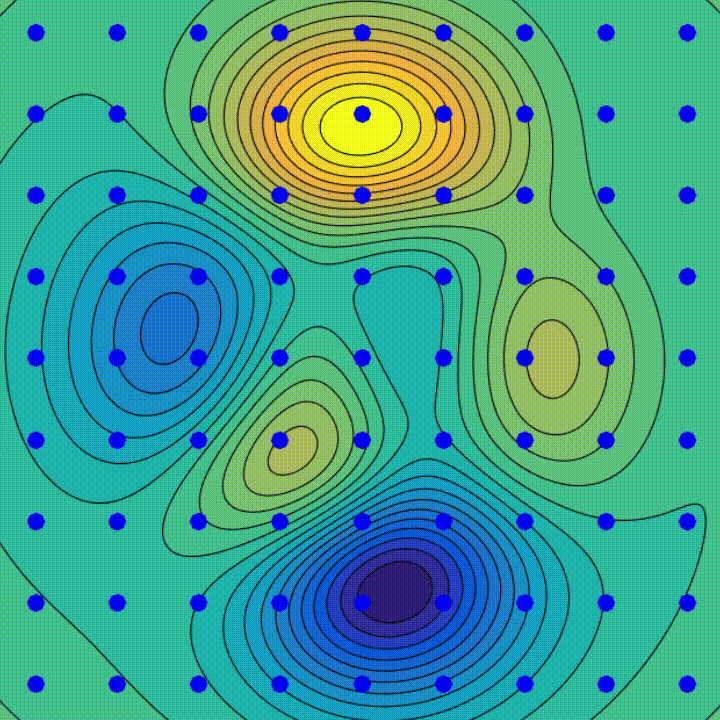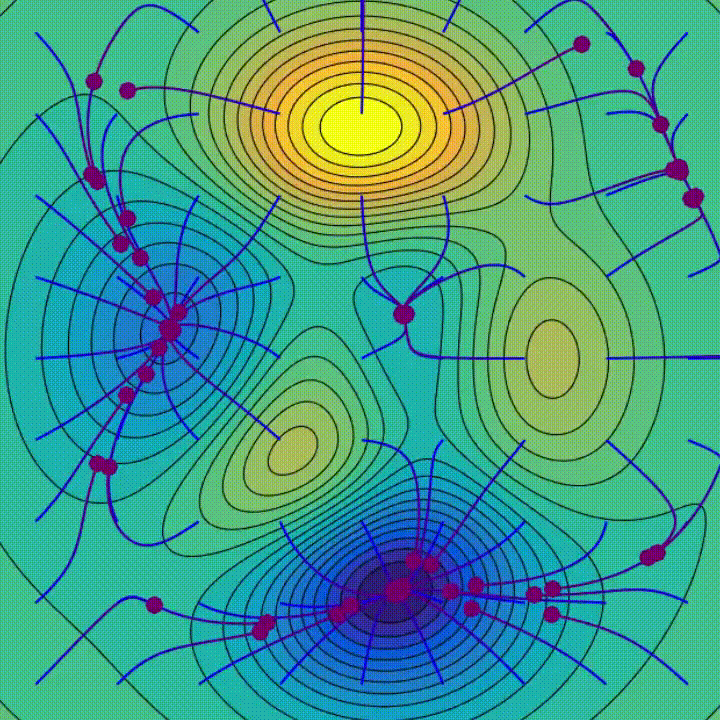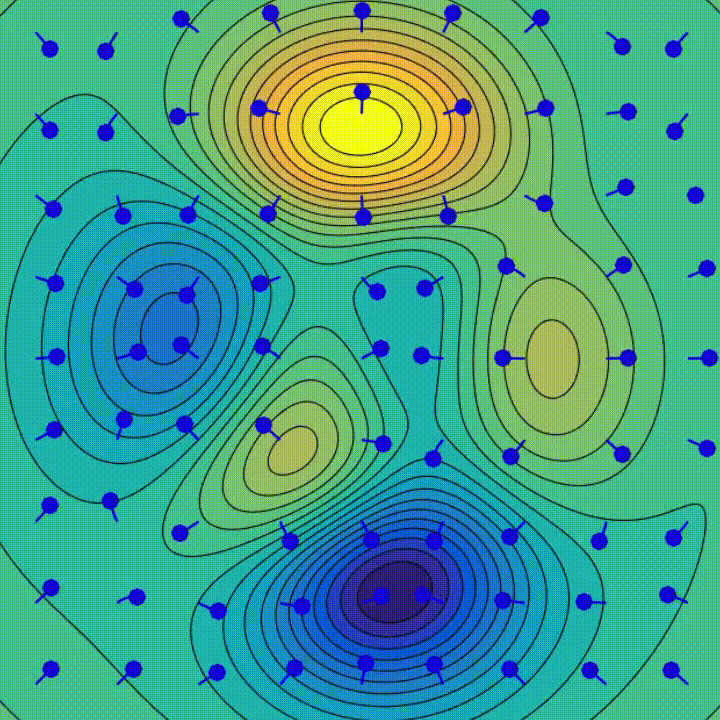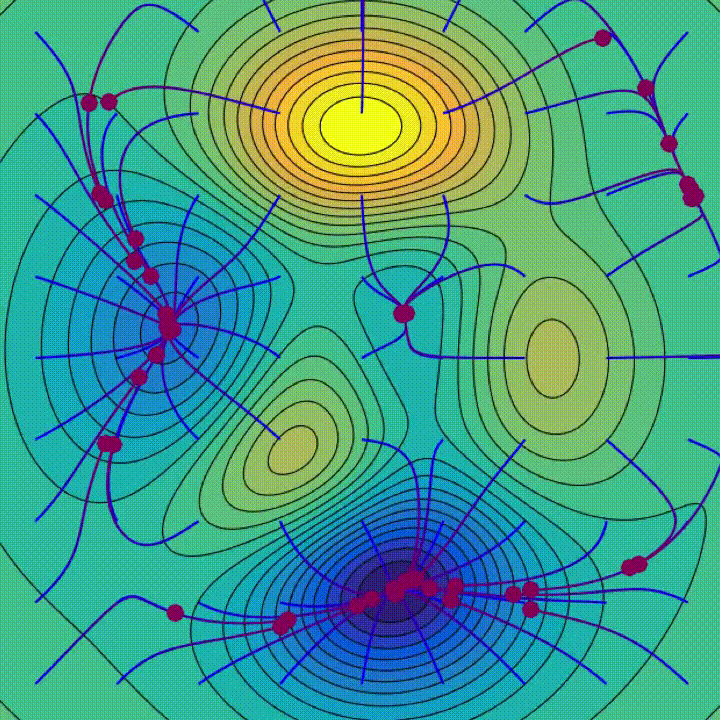
How does the optimiser make the network “learn”?
- The animation demonstrates the process for 2 parameters in 2D.
- Machine learning models have 100,000s of parameters.
- It’s difficult to visualise a ball rolling around in a multi-million dimensional space!
Dense layer
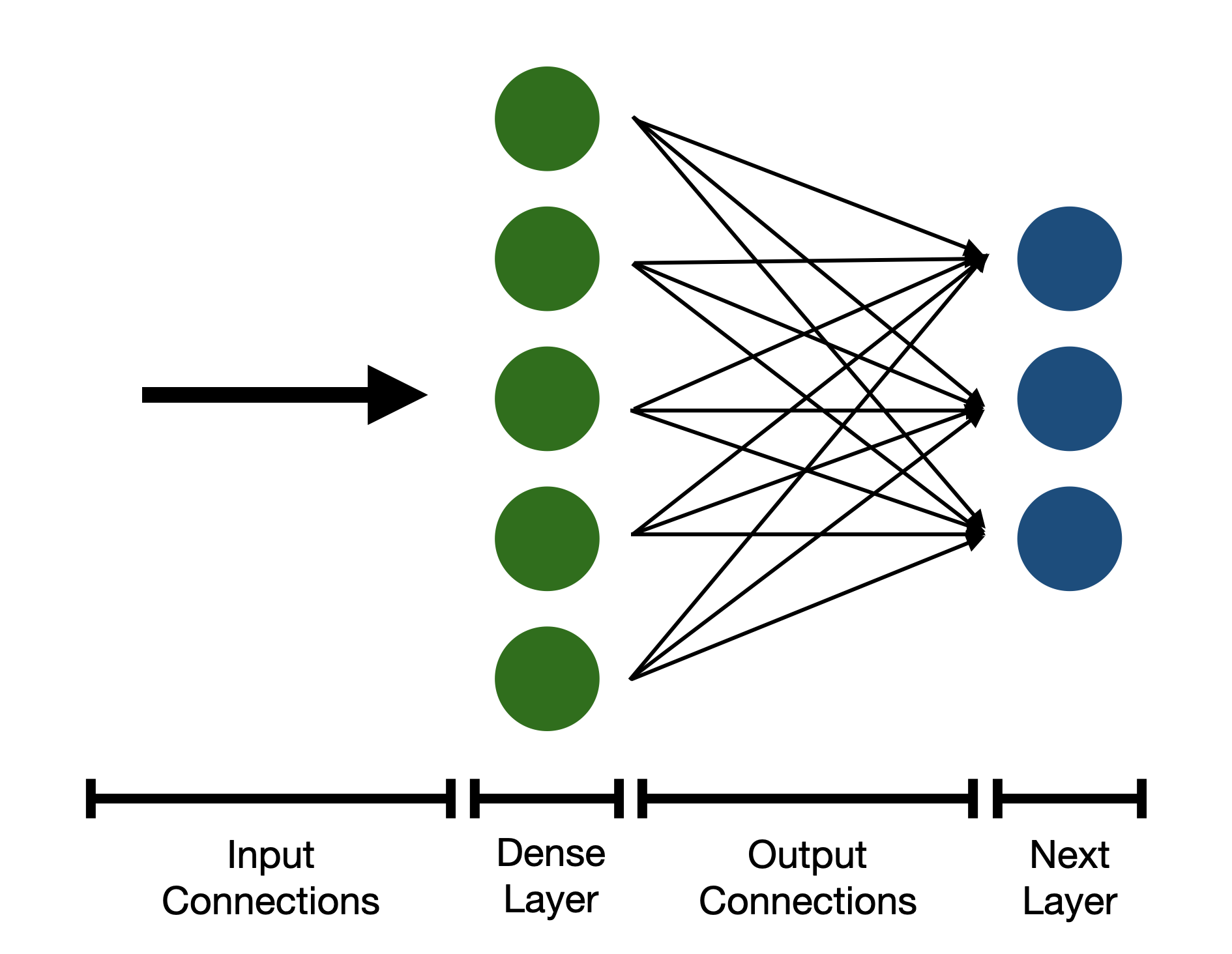
A diagram of a dense layer with 5 neurons, connected to another dense layer with 3 neurons.
The process of training
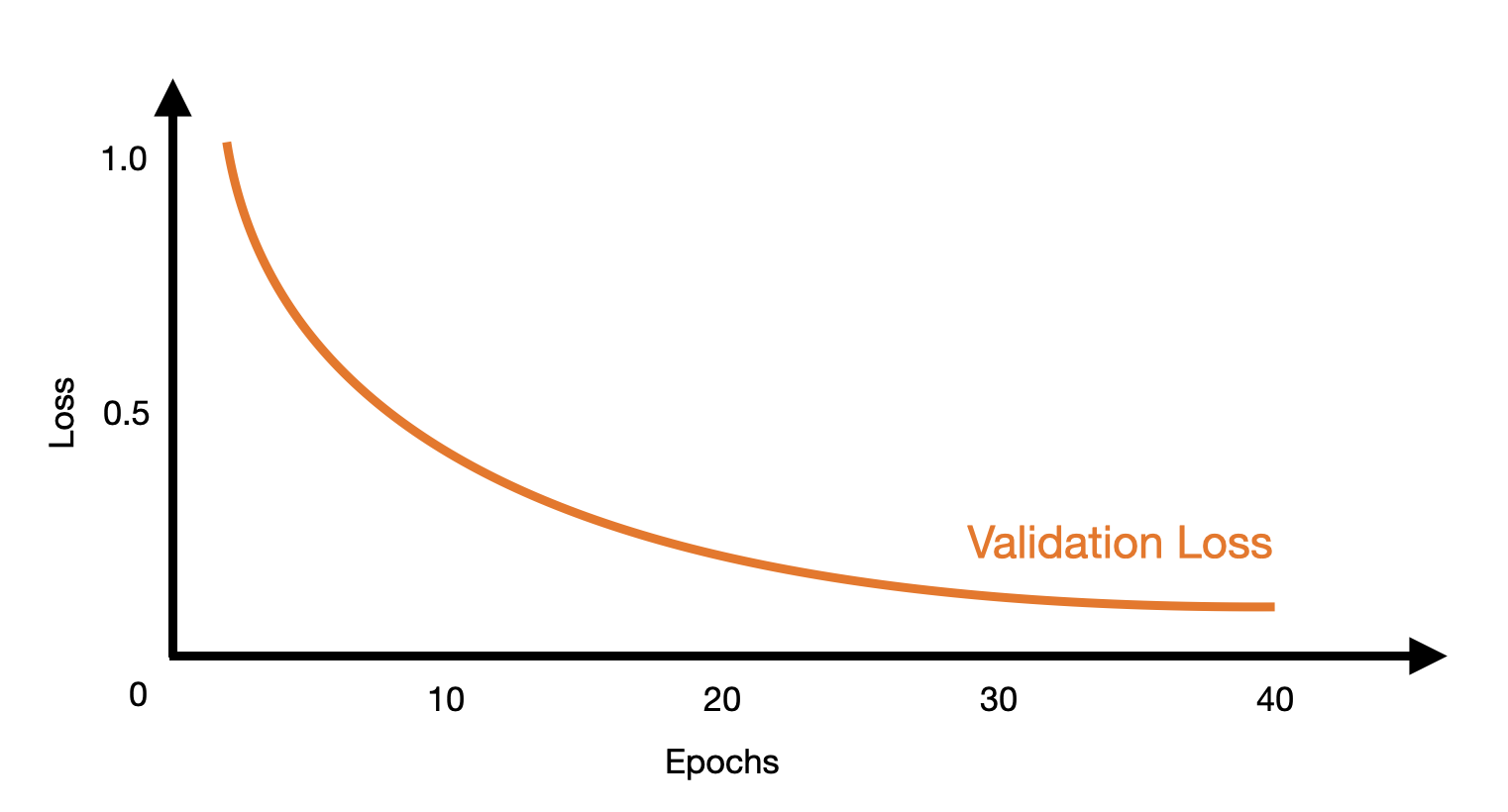
Number of epochs plotted against loss in an ideal situation.